

La détection d’anomalies est devenue essentielle à mesure que les entreprises cherchent à comprendre leurs données. Les outliers, ou valeurs aberrantes, sont ces points atypiques qui peuvent fausser les résultats d’analyse. L’apprentissage des métriques de distance (Distance Metric Learning) offre une approche novatrice pour quantifier la distance entre ces points de données. Au lieu de se fier à des métriques de distance classiques comme l’Euclidien ou le Manhattan, cette méthode apprend des données elles-mêmes ce qui constitue un écart significatif. Dans cet article, nous explorons comment cette technique peut transformer la manière dont nous identifions et traitons les outliers, son fonctionnement, et pourquoi elle pourrait devenir la norme dans le domaine de la science des données.
Comprendre les Outliers
Les outliers, ou anomalies, sont des valeurs qui se distinguent nettement du reste des données d’un ensemble. Ils peuvent être situés à l’écart de la distribution des points de données, se situant à des positions extrêmes par rapport aux autres observations. L’identification des outliers est cruciale pour de nombreuses raisons. Ils peuvent indiquer des erreurs dans les données, refléter des événements rares, ou révéler des comportements intéressants qui méritent une attention particulière. Par exemple, dans le domaine financier, un outlier pourrait signaler une fraude, tandis que dans la santé publique, il pourrait identifier une épidémie.
Pour détecter les outliers, plusieurs techniques et méthodes conventionnelles sont souvent utilisées. L’une des plus simples consiste à examiner les statistiques descriptives de l’ensemble de données, comme la moyenne et l’écart-type. Dans cette approche, tout point de données qui se trouve au-delà de deux ou trois écarts-types de la moyenne est souvent considéré comme un outlier. Bien que cette méthode soit facile à comprendre et à appliquer, elle peut être sensible aux valeurs extrêmes, ce qui peut fausser à la fois la moyenne et l’écart-type.
Une autre méthode courante repose sur l’utilisation de diagrammes de dispersion (ou scatter plots). En représentant les données graphiquement, il devient possible de visualiser les points qui se démarquent et d’apprécier leur répartition. Toutefois, cette méthode est limitée dans sa capacité à gérer des ensembles de données de grande dimension, où les visualisations deviennent rapidement complexes et difficiles à interpréter.

Un autre outil statistique utilisé pour identifier les outliers est le boxplot. Ce graphique divise les données en quartiles et met en évidence les points qui se trouvent en dehors des « whiskers » (moustaches), qui représentent généralement 1,5 fois l’écart interquartile. Les points situés au-delà sont considérés comme des anomalies. Cette méthode est efficace et visuelle, mais elle peut parfois masquer les anomalies lorsque la distribution des données est asymétrique.
D’autres techniques, comme les méthodes de clustering ou les modèles basés sur des arbres décisionnels, sont également appliquées pour identifier les outliers en analysant les groupes de données dans des dimensions multiples. Ces approches peuvent être particulièrement utiles lorsque l’on traite des données multidimensionnelles.
Dans l’ensemble, il est crucial de reconnaître que la détection des outliers n’est pas un problème de taille unique. Les méthodes choisies doivent être adaptées à la nature des données et à l’objectif de l’analyse. La détection des outliers est un élément clé dans l’analyse de données, surtout lorsque des décisions critiques reposent sur ces données. Pour approfondir la compréhension des outliers et des méthodologies de détection, vous pouvez visiter ce lien.
Les méthodes traditionnelles de mesure de distance
Lorsqu’il s’agit de mesurer les distances entre les points de données pour détecter des anomalies, plusieurs méthodes traditionnelles se démarquent par leur simplicité et leur accessibilité. Parmi celles-ci, la distance euclidienne, la distance de Manhattan et la distance de Gower sont fréquemment utilisées, chacune ayant ses propres caractéristiques, avantages et limites.

- Distance Euclidienne: Cette méthode calcule la distance « à vol d’oiseau » entre deux points dans un espace multidimensionnel. Elle est souvent considérée comme la norme en raison de sa compréhension intuitive et de sa capacité à bien fonctionner avec des données continues. Cependant, la distance euclidienne peut se révéler inappropriée pour des données à haute dimension, où elle peut être affectée par le phénomène de la « malédiction de la dimensionnalité », rendant la distinction entre les points proches et éloignés moins significative. En outre, elle ne peut pas gérer les données catégorielles, ce qui limite son application à des ensembles de données mixtes.
- Distance de Manhattan: Également connue sous le nom de distance « taxicab », la distance de Manhattan évalue la distance en se déplaçant uniquement le long des axes. Cette méthode est souvent plus robuste que la distance euclidienne dans le contexte des ensembles de données à faible variation, car elle est moins sensible aux valeurs extrêmes. Cependant, elle présente également des inconvénients, notamment une sensibilité aux données de haute dimension, où le nombre de dimensions dépasse celui des observations. Comme la distance euclidienne, la distance de Manhattan ne convient pas pour le traitement de données catégorielles.
- Distance de Gower: Contrairement aux deux précédentes, la distance de Gower est spécifiquement conçue pour gérer des ensembles de données mixtes, à savoir des données à la fois numériques et catégorielles. Cette méthode normalise les contributions aux distances en tenant compte des types de données, ce qui en fait un excellent choix pour des analyses complexes. Cependant, cette approche peut devenir plus complexe à calculer et à interpréter, surtout en présence de nombreux attributs, et elle peut également être plus sensible au bruit dans les données.

Dans le contexte de la détection des outliers, ces méthodes de mesure de distance jouent un rôle crucial, car elles influencent la façon dont les anomalies sont identifiées et interprétées. L’adéquation de chaque méthode peut considérablement varier selon la nature du dataset, et choisir la méthode de mesure de distance appropriée est essentiel pour obtenir des résultats fiables. Il est important d’évaluer les caractéristiques des données à analyser avant de décider quelle méthode appliquer, car cela déterminera l’efficacité et la précision de la détection des anomalies.
L’apprentissage des métriques de distance
L’apprentissage des métriques de distance représente une avancée significative par rapport aux méthodes traditionnelles qui ont été largement utilisées dans le cadre de la mesure des similarités entre les données. Alors que les méthodes classiques, telles que la distance euclidienne ou de Manhattan, ont leurs mérites, elles se heurtent souvent à des limites quand il s’agit de données complexes ou de grande dimension. C’est ici que l’apprentissage des métriques de distance se révèle particulièrement utile, offrant une flexibilité qui permet de mieux capturer des relations non linéaires et des interactions subtiles entre les différentes variables.
L’une des principales différences entre l’apprentissage des métriques de distance et les approches traditionnelles réside dans la capacité de cette méthode à apprendre directement à partir des données. Au lieu d’appliquer une métrique rigide et prédéfinie, comme la distance euclidienne, l’apprentissage des métriques permet de générer une distance personnalisée qui est optimisée en fonction des spécificités de l’ensemble de données étudié. Cela a pour effet de mieux refléter les véritables relations entre les points de données, entraînant ainsi une détection des anomalies plus précise.
En effet, l’apprentissage des métriques de distance utilise des techniques d’apprentissage supervisé ou non supervisé pour ajuster les paramètres de la distance afin qu’ils reflètent au mieux les corrélations au sein des données. Les approches comme la distance Mahalanobis, par exemple, mesurent les distances en tenant compte de la variance et de la covariance des données, permettant ainsi d’ajuster les distances en fonction de la structure des données elles-mêmes. Ce type d’adaptation peut se traduire par une meilleure performance dans des jeux de données hétérogènes ou présentant des variations significatives.

Les avantages de cette dynamique adaptative sont encore plus marqués dans des contextes caractéristiques de données réelles, où des relations complexes peuvent souvent être présentes. Contrairement aux méthodes classiques qui ont tendance à être linéaires et souvent simplistes, l’apprentissage des métriques de distance invite à explorer des relations plus nuancées, contribuant ainsi à une détection d’anomalies plus efficace. En multipliant les relations complexes, le risque de fausses détections d’anomalies est considérablement réduit.
Par ailleurs, cette approche peut également faciliter la fusion de différentes sources de données, ce qui est un défi majeur dans le traitement des données réelles. Par exemple, lorsque des données numériques sont combinées avec des données catégoriques, les méthodes traditionnelles de distance peuvent générer des résultats trompeurs, tandis que l’apprentissage des métriques peut normaliser ces disparités et s’adapter de manière à fournir des comparaisons significatives.
Le potentiel de l’apprentissage des métriques de distance ne se limite pas simplement à son application sur les données, mais s’étend également à son impact sur la création de modèles prédictifs, notamment dans des applications telles que la détection d’anomalies.
Mise en pratique avec les forêts aléatoires
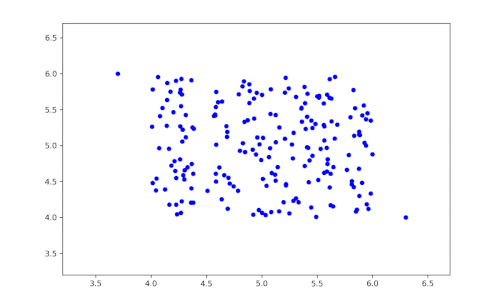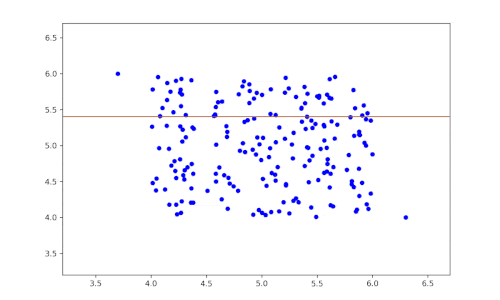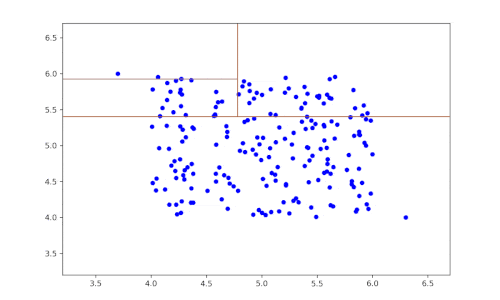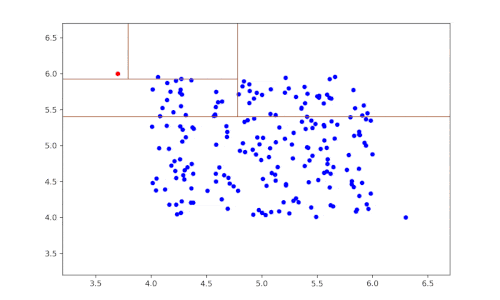
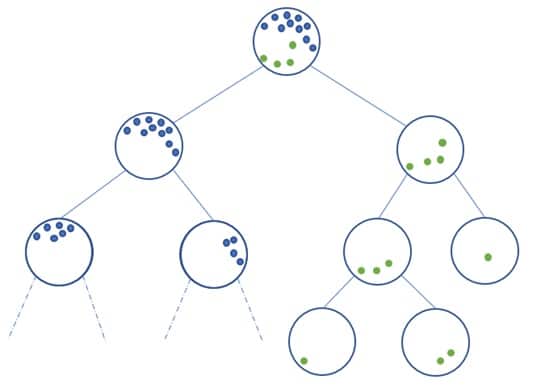
Pour appliquer l’apprentissage des métriques de distance dans la détection d’anomalies, l’une des méthodes populaires et efficaces est l’utilisation des forêts aléatoires. Ce modèle d’ensemble, qui se compose de plusieurs arbres de décision, est capable de classifier et de détecter des anomalies en raison de sa robustesse et de sa capacité à capturer des interactions complexes au sein des données. Dans ce chapitre, nous allons explorer les étapes pratiques pour créer un modèle de détection d’anomalies basé sur des forêts aléatoires.

La première étape consiste à préparer les données. Cela implique de nettoyer les données, de gérer les valeurs manquantes et de normaliser les caractéristiques si nécessaire. Étant donné que les mesures de distance peuvent être affectées par des différences d’échelle, la normalisation garantit que chaque dimension contribue également au calcul des distances. Une fois les données prêtes, il est essentiel de séparer un ensemble de données d’entraînement et un ensemble de test pour évaluer les performances du modèle. Cette séparation permet d’éviter le surapprentissage, une situation où le modèle performe bien sur l’ensemble d’entraînement tout en échouant à généraliser sur de nouvelles données.
La prochaine étape est la construction du modèle. Pour créer la forêt aléatoire, on commence par définir le nombre d’arbres à inclure dans la forêt. Un nombre plus élevé d’arbres peut améliorer la stabilité et la précision des prédictions, mais peut également augmenter le temps de calcul. Ensuite, chaque arbre de la forêt est construit en utilisant un sous-ensemble de données d’entraînement, ce qui introduit une variabilité nécessaire pour une meilleure généralisation. Les critères d’impureté tels que l’indice de Gini ou l’entropie peuvent être utilisés pour déterminer la qualité des séparations à chaque nœud des arbres.
Une fois le modèle formé, l’étape suivante consiste à évaluer les performances du modèle. Cela se fait en utilisant l’ensemble de test pour prédire les classes. Les anomalies sont généralement marquées comme des instances qui appartiennent à une classe minoritaire ou qui dépassent un certain seuil de distance par rapport aux autres données. Les résultats peuvent être évalués à l’aide de différentes métaphores telles que la courbe ROC, la précision, le rappel, et le score F1. Cela permet d’analyser comment le modèle se comporte face à la détection d’anomalies.
Enfin, il est essentiel de optimiser le modèle. Cela peut impliquer l’ajustement des paramètres d’hyperparamétrage tels que la profondeur maximale des arbres, le nombre minimum d’échantillons pour une feuille, ou le nombre maximal de caractéristiques à considérer lors de la recherche des meilleures séparations. Une approche de validation croisée peut être utilisée pour garantir que le modèle est à la fois performant et généralisable. Pour plus d’informations sur les forêts aléatoires et leur application, vous pouvez consulter des ressources détaillées sur le site IBM ici.
Exemples et études de cas
Les exemples et études de cas en matière d’apprentissage des métriques de distance pour la détection d’anomalies mettent en lumière l’efficacité et l’applicabilité de ces méthodes dans divers domaines. L’un des cas concrets les plus marquants provient de l’analyse des transactions financières. Une étude réalisée sur un ensemble de données de transactions a utilisé des métriques de distance pour identifier des transactions potentiellement frauduleuses. En appliquant des algorithmes de clustering comme DBSCAN, les chercheurs ont pu isoler un ensemble de transactions qui se démarquaient des autres par leur comportement atypique. Cela a permis d’augmenter le taux de détection des fraudes, tout en réduisant le nombre de faux positifs, ce qui est souvent un défi majeur dans le secteur financier.
Une autre étude intéressante a été menée dans le domaine de la santé. Dans ce contexte, des métriques de distance ont été employées pour détecter des anomalies dans les données des patients, notamment dans le suivi des maladies chroniques. En utilisant des distances basées sur des caractéristiques telles que les signes vitaux et les antécédents médicaux, les chercheurs ont pu identifier des patients dont les profils évoluaient de manière inattendue, signalant ainsi la nécessité d’une attention médicale immédiate. Cette approche a montré un potentiel significatif pour améliorer les résultats cliniques en permettant une intervention précoce.
Il est essentiel de comparer ces approches basées sur des métriques de distance avec d’autres méthodes traditionnelles de détection d’anomalies, comme le modèle de régression ou les modèles basés sur le Machine Learning supervisé. Les méthodes traditionnelles, bien qu’efficaces, reposent souvent sur des hypothèses qui peuvent ne pas tenir compte des complexités des données réelles. Par exemple, les modèles de régression peuvent ne pas capturer des non-linéarités complexes, tandis que les approches supervisées nécessitent un ensemble de données étiquetées qui peut être difficile à obtenir pour certaines anomalies rares.
En opposition à cela, l’utilisation des métriques de distance permet une flexibilité accrue et une adaptation à la structure des données. Les études ont montré que parfois, les approches non supervisées, représentant un modèle d’une plus grande robustesse, peuvent surpasser les méthodes traditionnelles en identifiant des structures sous-jacentes non détectées. De plus, la capacité d’analyser des données de manière multi-dimensionnelle à l’aide de métriques variées (comme euclidienne, de Manhattan, ou même des distances basées sur des distributions) constitue un avantage non négligeable dans les contextes où les anomalies sont interconnectées et influencées par des facteurs multiples.
En matière d’expérimentations, les résultats ont également démontré que ces méthodes d’apprentissage des métriques de distance peuvent être adaptées à divers ensembles de données, que ce soit en environnement industriel pour détecter des défauts de fabrication ou tout simplement dans des systèmes de surveillance réseau pour identifier des comportements anormaux. Ce champ d’étude ouvre la voie à des innovations continues, augmentant ainsi notre capacité à détecter les anomalies dans des scénarios complexes et variés.
Limites et perspectives de l’apprentissage des métriques de distance
L’apprentissage des métriques de distance pour la détection des anomalies offre de nombreuses opportunités, mais il comporte également certaines limites qu’il est essentiel de reconnaître. Une des principales limites réside dans la dépendance à la qualité et à la quantité des données. Les systèmes d’apprentissage supervisé, qui incluent souvent l’apprentissage des métriques de distance, peuvent souffrir lorsqu’ils sont alimentés par des ensembles de données biaisés ou peu représentatifs . Les caractéristiques des données d’entraînement peuvent influencer de manière significative la performance du modèle dans des contextes réels, entraînant ainsi une suridentification ou une sous-identification des anomalies.
De plus, la complexité des métriques de distance elles-mêmes peut être un obstacle. Alors que certaines métriques, comme la distance euclidienne, sont simples, d’autres peuvent être plus compliquées à interpréter et à calibrer. Par exemple, les distances basées sur des noyaux ou des métriques apprises peuvent requérir des calculs intensifs et des ajustements fins, ce qui peut accroître le coût computationnel et le temps nécessaire pour l’entraînement du modèle. Cela soulève des questions sur la faisabilité de leur application dans des environnements en temps réel où le traitement rapide des données est crucial.
Une autre limite concerne l’extensibilité du modèle. À mesure que le volume de données augmente, certaines méthodes d’apprentissage des métriques de distance peuvent devenir moins efficaces en raison de la « malédiction de la dimensionnalité ». Dans ces cas, la performance peut diminuer, et les anomalies peuvent devenir difficilement détectables au milieu d’un grand nombre de points de données.
Pour faire face à ces défis, il est essentiel de développer des approches robustes qui combinent des métriques de distance avec des techniques d’apprentissage automatique plus complètes. Par exemple, intégrer des méthodes d’ensemble ou hybrides pourrait améliorer la résilience des modèles face à des données imparfaites. De même, il serait pertinent d’explorer l’utilisation de techniques de réduction de dimensionnalité pour faciliter le traitement des données tout en conservant la structure sous-jacente des informations pertinentes.
Par ailleurs, les recherches futures pourraient se concentrer sur l’intégration de méthodes de validation croisée plus précises qui permettraient d’évaluer la généralité des modèles construits à partir des métriques de distance. L’exploration de nouveaux algorithmes, comme ceux basés sur l’apprentissage par renforcement, pourrait également offrir des perspectives intéressantes pour améliorer la détection des anomalies dans des contextes dynamiques et évolutifs.
En somme, bien que l’apprentissage des métriques de distance représente une avancée significative dans la détection des anomalies, il est impératif de continuer à identifier et à surmonter ses limitations par des recherches ciblées et des innovations théoriques. Cela pourrait faciliter l’adoption de ces techniques dans des applications réelles, augmentant ainsi notre capacité à détecter les anomalies dans un large éventail de domaines, y compris la finance, la santé, et l’industrie.
Conclusion
En somme, l’apprentissage des métriques de distance se présente non seulement comme une solution pour la détection des anomalies, mais aussi comme un outil polyvalent appliqué à diverses tâches d’analyse de données. L’approche basée sur les forêts aléatoires, comme illustré dans l’article, permet de mieux comprendre les relations complexes entre les données. Bien qu’aucune méthode ne soit infaillible, la puissance de l’apprentissage des métriques de distance réside dans sa capacité à relever ces subtilités là où des métriques traditionnelles échouent. Cela demande un certain paramétrage pour produire des données synthétiques réalistes, c’est vrai, mais les résultats peuvent être significativement meilleurs. En fin de compte, adopter cette approche, éventuellement en conjonction avec d’autres techniques de détection, pourrait bien devenir incontournable dans la boîte à outils d’un analyste de données. L’apprentissage des métriques de distance mérite une place centrale dans le débat sur l’avenir de l’analyse des données et la détection des anomalies.
FAQ
Qu’est-ce qu’un outlier ?
Les outliers sont des valeurs dans un ensemble de données qui diffèrent significativement des autres points, ce qui peut les rendre difficiles à analyser ou interpréter.
Pourquoi l’apprentissage des métriques de distance est-il important ?
Cette méthode permet d’adapter la mesure de distance aux données elles-mêmes, offrant une précision améliorée pour identifier les outliers en prenant en compte la structure de l’ensemble de données.
Quelles sont les méthodes classiques de détection des outliers ?
Parmi les méthodes traditionnelles, on trouve l’Euclidean, le Manhattan, et le Gower, chacune ayant ses propres avantages et inconvénients selon le type de données utilisées.
Comment fonctionne une forêt aléatoire dans ce contexte ?
Les forêts aléatoires sont utilisées pour créer un modèle qui peut distinguer entre les données réelles et synthétiques, permettant une évaluation plus précise des outliers en se basant sur les chemins de décision à travers les arbres.
L’apprentissage des métriques de distance peut-il être combiné avec d’autres techniques ?
Oui, il est souvent avantageux de combiner cette technique avec d’autres méthodes de détection d’anomalies pour améliorer la robustesse et la fiabilité des résultats obtenus.
⭐ Analytics engineer, Data Analyst et Automatisation IA indépendant ⭐
- Ref clients : Logis Hôtel, Yelloh Village, BazarChic, Fédération Football Français, Texdecor…
Mon terrain de jeu :
- Data Analyst & Analytics engineering : tracking avancé (GTM server, e-commerce, CAPI, RGPD), entrepôt de données (BigQuery, Snowflake, PostgreSQL, ClickHouse), modèles (Airflow, dbt, Dataform), dashboards décisionnels (Looker, Power BI, Metabase, SQL, Python).
- Automatisation IA des taches Data, Marketing, RH, compta etc : conception de workflows intelligents robustes (n8n, App Script, scraping) connectés aux API de vos outils et LLM (OpenAI, Mistral, Claude…).
- Engineering IA pour créer des applications et agent IA sur mesure : intégration de LLM (OpenAI, Mistral…), RAG, assistants métier, génération de documents complexes, APIs, backends Node.js/Python.