
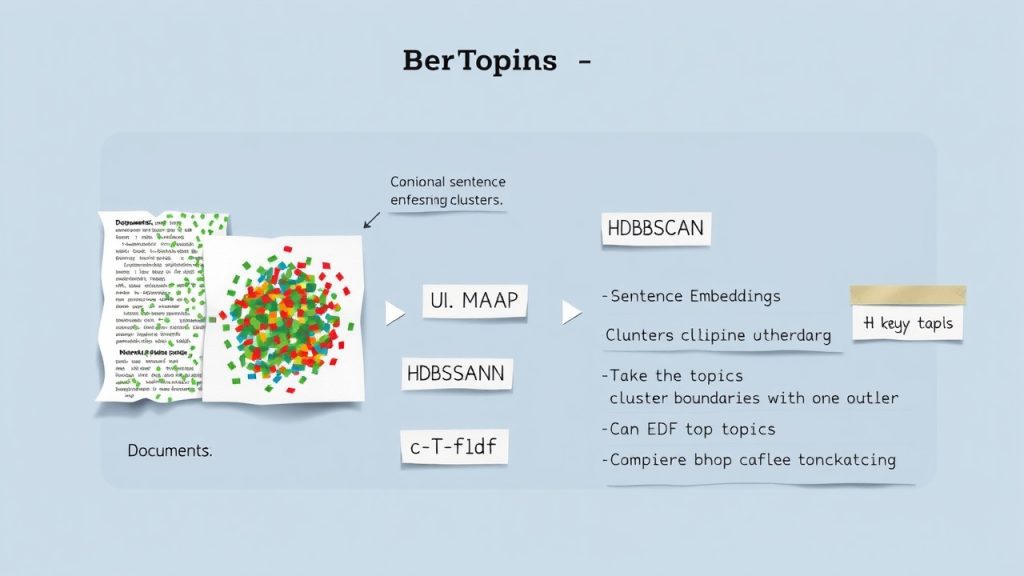
BERTopic convertit des textes en embeddings sémantiques, réduit la dimension, regroupe les documents et extrait des mots-clés via c‑TF‑IDF (voir Maarten Grootendorst — GitHub; SentenceTransformers, UMAP, HDBSCAN). Suivez la pipeline et ses paramètres clé pour des topics interprétables.
Qu’est-ce que BERTopic
BERTopic combine plusieurs briques pour extraire des topics sémantiques à partir de textes : embeddings pour capturer le sens, réduction de dimension pour rendre les vecteurs exploitables, clustering pour regrouper les documents et c‑TF‑IDF pour rendre les topics interprétables.
Embeddings (SentenceTransformers)
Les embeddings transforment chaque document en un vecteur numérique qui capture le sens à un niveau phrase/document. Les modèles de Reimers & Gurevych (SentenceTransformers) offrent des embeddings de haute qualité prêts à l’emploi.

À surveiller :
- Choix du modèle : Des modèles plus grands (par ex. SBERT large) améliorent la qualité mais augmentent la latence et la mémoire.
- Domaine spécifique : Les embeddings génériques peuvent rater le jargon ; il faut parfois fine-tuner ou choisir un modèle spécialisé.
- Coût : Inférence à grande échelle peut nécessiter GPU ou infrastructure coûteuse.
Source : Sentence-Transformers (Reimers & Gurevych), bibliothèque sentence-transformers.
Réduction de dimension (UMAP)
La réduction de dimension via UMAP (McInnes et al.) projette les embeddings dans un espace de faible dimension tout en conservant la structure locale, ce qui facilite le clustering.

À surveiller :
- Paramètres (n_neighbors, min_dist) : Influencent fortement la géométrie résultante et donc le clustering.
- Coût algorithmique : UMAP est plus rapide que t-SNE mais reste coûteux sur très grands jeux de données.
Source : UMAP (McInnes, Healy, Nathan).
Clustering (HDBSCAN)
HDBSCAN (Campello et al.) identifie clusters denses et marque les points clairsemés comme outliers, sans avoir à fixer le nombre de clusters a priori.

À surveiller :
- Sensibilité aux paramètres (min_cluster_size, min_samples) : Change la granularité et la détection d’outliers.
- Complexité : Calcul intensif sur grandes dimensions ; bénéfice réel après réduction (UMAP).
Source : HDBSCAN (Campello et al.), bibliothèque hdbscan.
Représentation des topics (c‑TF‑IDF)
Le c‑TF‑IDF (class-based TF‑IDF) calcule l’importance des termes par cluster plutôt que par document, permettant d’extraire des mots-clés représentatifs pour chaque topic.

À surveiller :
- Sensibilité au prétraitement : Tokenisation, lemmatisation et stopwords influencent fortement les termes retenus.
- Interprétabilité : Fonctionne bien pour labels simples mais peut mélanger synonymes sans normalisation.
Source : Implémentation et usage dans BERTopic (Maarten Grootendorst).
| Critère | BERTopic | LDA (classique) |
| Besoin de prétraitement | Moindre pour le sens (embeddings), mais tokenisation/stopwords utiles pour c‑TF‑IDF. | Élevé : Lemmes, stopwords et segmentation nécessaires. |
| Capacité à capter le sens | Élevée grâce aux embeddings sémantiques. | Limitée : Basée sur cooccurrences statistiques. |
| Sensibilité aux stopwords | Modérée : Embeddings atténuent l’impact, c‑TF‑IDF reste sensible. | Forte : Stopwords faussent rapidement les topics. |
| Interprétabilité | Bonne : Labels par c‑TF‑IDF + exemples de documents. | Variable : Topics souvent moins cohérents sémantiquement. |
Comment sont créés les embeddings
Les embeddings sont des vecteurs denses produits par des modèles de type SentenceTransformers qui codent le sens global d’un document en quelques centaines de dimensions, facilitant la comparaison sémantique entre textes.
Principaux avantages des embeddings par rapport au sac-of-words :
- Captent le contexte et l’ordre des mots : Un vecteur encode la phrase entière, pas seulement la fréquence de mots.
- Gèrent la synonymie : Des phrases différentes mais similaires sémantiquement se retrouvent proches dans l’espace vectoriel.
- Atténuent la polysémie : Le sens est détaché du seul mot isolé grâce au contexte environnant.

Choix de modèles et compromis latence / qualité / empreinte mémoire :
- Modèles compacts (ex. all-MiniLM-L6-v2) : Vecteurs de taille 384, faible latence et faible empreinte mémoire, idéal pour prototypes et production à grande échelle.
- Modèles intermédiaires (ex. all-mpnet-base-v2) : Vecteurs de taille 768, meilleure qualité sémantique, coût CPU/GPU et mémoire supérieur.
- Modèles lourds (ex. modèles basés sur parXlarge) : Qualité maximale pour tâches fines, mais latence élevée et empreinte importante — à réserver aux cas d’usage critique.
Exemple de code Python minimal :
from sentence_transformers import SentenceTransformer
# Charge un modèle compact
model = SentenceTransformer('all-MiniLM-L6-v2')
# Liste de documents
docs = ["Bonjour le monde.", "Analyse de topics avec BERTopic.", "Embeddings sémantiques."]
# Encode et affiche la forme du tenseur résultant
embeddings = model.encode(docs, show_progress_bar=False)
print("Shape des embeddings :", embeddings.shape) # (3, 384)Prétraitement recommandé :
- Minuscules et suppression d’espaces : Normalise sans perdre le sens.
- Filtrage des documents trop courts : Élimine les bruits (par ex. moins de 3 tokens).
- Éviter la lemmatisation lourde : La lemmatisation peut écraser des nuances (temps, négations, entités) que le modèle contextualisé exploite.
Tableau comparatif rapide :
| Nom | Dimension | Latence relative | Usage recommandé |
| all-MiniLM-L6-v2 | 384 | Très faible | Production à grande échelle, prototypes |
| all-mpnet-base-v2 | 768 | Moyenne | Analyses sémantiques précises |
| Modèles large (ex. distil/large) | 768–1024+ | Élevée | Cas critiques nécessitant une qualité maximale |
Pourquoi UMAP et HDBSCAN
UMAP réduit la dimensionnalité des embeddings en conservant la structure locale des données, ce qui rend le clustering plus simple, plus rapide et plus robuste. Réduire la dimension facilite la visualisation (2D/3D), diminue la complexité algorithmique et atténue le bruit haute-dimensionnel qui perturbe souvent les algorithmes de densité.
UMAP préserve les voisinages via n_neighbors (nombre de voisins considérés) et compacte l’information en n_components. Question clé : pourquoi réduire avant de clusteriser ? Parce qu'une représentation à faible dimension met en évidence des densités locales exploitables par HDBSCAN, réduit le coût mémoire/CPU (souvent ×10 ou plus selon la taille d'embedding) et stabilise les frontières entre topics.
HDBSCAN est un algorithme hiérarchique basé sur la densité qui identifie d'abord des régions denses puis extrait des clusters stables depuis une dendrogramme de densité. HDBSCAN n'impose pas de nombre de clusters fixe ; il détecte automatiquement des groupes de densités variables et marque les points non assignables comme outliers (label -1). Ceci est précieux pour des corpus hétérogènes contenant documents mixtes, spam ou documents très courts : les outliers évitent de polluer les topics pertinents.
- Recommandations pratiques : Commencer UMAP avec n_neighbors=15–50 ; n_components=5–50 selon tâche (5–15 pour clustering, 2–3 pour visualisation) ; min_dist=0.0–0.3 pour garder localité.
- Pour HDBSCAN : min_cluster_size=5–50 (5 pour fine granularité, 30+ pour topics stables) ; cluster_selection_epsilon≈0.0–0.5 pour contrôler séparation fine.
from umap import UMAP
import hdbscan
# Réduction UMAP
umap_model = UMAP(n_neighbors=30, n_components=15, min_dist=0.1, metric='cosine')
# Clustering HDBSCAN
hdb_model = hdbscan.HDBSCAN(min_cluster_size=15,
cluster_selection_epsilon=0.0,
metric='euclidean',
prediction_data=True)
Explication succincte des paramètres : n_neighbors contrôle la granularité locale (↑ → captures structures globales, ↓ → plus local), min_dist contrôle la compaction des points, min_cluster_size fixe la taille minimale d'un topic stable et cluster_selection_epsilon permet de fusionner clusters proches.
| Paramètre | Rôle | Valeur de départ |
| n_neighbors (UMAP) | Échelle locale vs globale des voisinages | 30 |
| n_components (UMAP) | Dimension de sortie (représentation) | 15 (pour clustering) |
| min_dist (UMAP) | Compaction des points similaires | 0.1 |
| min_cluster_size (HDBSCAN) | Taille minimale d’un cluster | 15 |
| cluster_selection_epsilon (HDBSCAN) | Seuil pour fusionner clusters proches | 0.0 |
Comment c‑TF‑IDF rend les topics interprétables et un mini exemple
Voici comment c‑TF‑IDF rend les topics interprétables et un mini‑exemple chiffré.
c‑TF‑IDF se calcule conceptuellement ainsi : c‑TF‑IDF = TF_classe × log(Total_docs / Docs_in_class). TF_classe représente la fréquence normalisée d’un mot au sein d’un cluster (compte du mot / total mots du cluster). Le terme log(Total_docs / Docs_in_class) est une « inverse class frequency » : il pénalise les mots présents dans de nombreux clusters et valorise ceux spécifiques à peu de clusters.
| Mot | Count C0 | TF C0 | Count C1 | TF C1 | IDF C0 | IDF C1 | c‑TF‑IDF C0 | c‑TF‑IDF C1 |
| chat | 3 | 0.60 | 0 | 0.00 | 0.405 | 1.099 | 0.243 | 0.000 |
| chien | 1 | 0.20 | 2 | 0.67 | 0.405 | 1.099 | 0.081 | 0.732 |
| souris | 1 | 0.20 | 0 | 0.00 | 0.405 | 1.099 | 0.081 | 0.000 |
| arbre | 0 | 0.00 | 1 | 0.33 | 0.405 | 1.099 | 0.000 | 0.366 |
BERTopic utilise ces scores pour ordonner les mots par topic : il calcule c‑TF‑IDF par topic puis sélectionne les top‑n mots avec les plus hauts scores, fournissant ainsi des labels interprétables.
| Topic ID | Taille | Top 5 mots |
| 0 | 2 | chat, chien, souris |
| 1 | 1 | chien, arbre |
Installer les dépendances : pip install bertopic umap-learn hdbscan sentence-transformers.
from bertopic import BERTopic
from sklearn.feature_extraction.text import CountVectorizer
from sentence_transformers import SentenceTransformer
docs = ["chat chat chien", "chat souris", "chien chien arbre"]
emb = SentenceTransformer("all-MiniLM-L6-v2")
doc_embeddings = emb.encode(docs, show_progress_bar=False)
topic_model = BERTopic(embedding_model=emb)
topics, probs = topic_model.fit_transform(docs, embeddings=doc_embeddings)
print(topic_model.get_topic_info())
print(topic_model.get_topics()) # top words per topicPour nettoyer des topics redondants, fusionner les topics proches, réduire le nombre de mots par topic (n_words), retravailler le pré‑traitement (stopwords, lemmatisation) ou ajuster HDBSCAN/UMAP (min_cluster_size, n_neighbors) sont les leviers principaux.
| Étape | Sortie | Action de tuning |
| Encodage | Embeddings | Changer le modèle (précision vs vitesse) |
| Réduction (UMAP) | Représentation 2‑D/Low‑D | Ajuster n_neighbors, min_dist |
| Clustering (HDBSCAN) | Clusters / Topics | Modifier min_cluster_size, seuils |
| c‑TF‑IDF | Top mots par topic | Filtrer stopwords, ngram_range, n_words |
Prêt à lancer BERTopic sur vos jeux de données ?
BERTopic combine embeddings modernes, réduction dimensionnelle, clustering adaptatif et c‑TF‑IDF pour produire des topics sémantiques et interprétables sans prétraitement excessif. En pratique vous gagnez en qualité d’interprétation par rapport aux approches basées uniquement sur TF‑IDF, tout en gardant la flexibilité de paramétrage (UMAP/HDBSCAN). Testez la pipeline sur un sous-ensemble, ajustez n_neighbors et min_cluster_size, puis étendez. Bénéfice pour vous : obtenir des topics exploitables rapidement pour l’analyse, la synthèse et la prise de décision.
FAQ
A propos de l’auteur
Je suis Franck Scandolera, expert & formateur en tracking avancé server-side, Analytics Engineering, automatisation No/Low Code (n8n) et intégration de l’IA en entreprise. J’accompagne des acteurs comme Logis Hôtel, Yelloh Village, BazarChic, la Fédération Française de Football et Texdecor. Responsable de l’agence webAnalyste et de l’organisme Formations Analytics. Dispo pour aider les entreprises => contactez moi.
⭐ Analytics engineer, Data Analyst et Automatisation IA indépendant ⭐
- Ref clients : Logis Hôtel, Yelloh Village, BazarChic, Fédération Football Français, Texdecor…
Mon terrain de jeu :
- Data Analyst & Analytics engineering : tracking avancé (GTM server, e-commerce, CAPI, RGPD), entrepôt de données (BigQuery, Snowflake, PostgreSQL, ClickHouse), modèles (Airflow, dbt, Dataform), dashboards décisionnels (Looker, Power BI, Metabase, SQL, Python).
- Automatisation IA des taches Data, Marketing, RH, compta etc : conception de workflows intelligents robustes (n8n, App Script, scraping) connectés aux API de vos outils et LLM (OpenAI, Mistral, Claude…).
- Engineering IA pour créer des applications et agent IA sur mesure : intégration de LLM (OpenAI, Mistral…), RAG, assistants métier, génération de documents complexes, APIs, backends Node.js/Python.